Helping data publishers to improve open data: research and tools register.
Gender
 2018-05-14 10:59:29
2018-05-14 10:59:29 Source : https://theodi.org/article/to-improve-open-data-help-publishers/
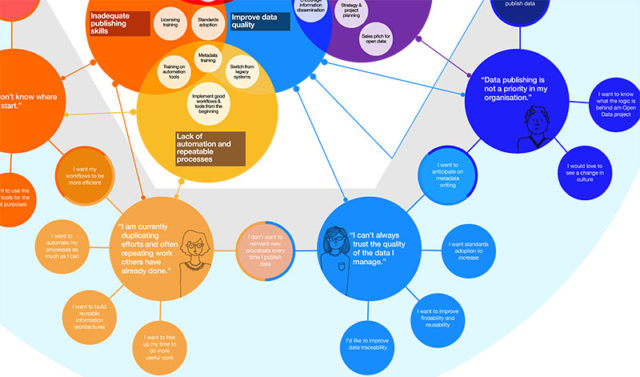
In our quest to help speed up and automate the process of publishing high-quality open data, we spent a few months listening to the people whose role it was to publish data, and the people creating tools for them. This is what we learned By Olivier Thereaux Read the report: What data publishers need: research and recommendations A few months ago, we published a blog-post introducing some of our work on improving open data publishing. By asking the question: “How can better publishing tools improve the quality, speed and cost-effectiveness of data publishing”, we were hoping to generate novel insights compared to the traditional approach of focusing more on people finding and using open data. Our research The discovery phase of our research, lasting for most of the summer and early autumn of 2017, aimed to help us understand: Who are the main actors in the open data publishing landscape? What pain points do data publishers face when publishing data? What are the potential solutions to these pain points? Discovery involved mainly two activities: an audit of existing data publishing tools, and user research. The audit looked at more than 30 different tools: who makes them, who they are for, what type of data they are used for, what business model they operate on, whether they’re mature tools or not, etc. This audit helped us understand whether there was any gaping hole in the current tools landscape (answer: not really, but the devil is in the detail), or whether there was any obvious issue with the ecosystem. We want this research to be helpful to others too, so we have made our Publishing Tools Register public, and are now planning to work with the open data community to make it more than yet-another-tools-list: something truly useful and sustainable.